2025. 1. 12. 13:46ㆍFramework/NestJS
최근 사내에서 진행한 결제 프로젝트는 NestJS라는 새로운 프레임워크를 도입해서 진행했습니다. 현재 가장 큰 문제점은 오류가 발생했을 때 그 오류를 로컬 환경에서 재현하지 않으면 오류의 원인을 명확히 알 수 없는 상황이었습니다. 물론 현재는 Sentry Report를 통해서 오류가 발생했을 때 원인을 알 수 있도록 시니어 개발자분께서 환경세팅을 해주셨지만 Sentry는 메트릭과 관련된 데이터를 모니터링하는 것에는 한계가 있었습니다.
그래서 이번 포스팅에서는 Grafana, Loki, Promtail, Prometheus를 사용해서 실시간 로그 수집과 메트릭을 모니터링해 본 경험을 공유해보려고 합니다. 아직 사내에서 정식 채택되어 사용하지는 못했지만, 지속적인 공유와 디벨롭을 통해서 가까운 미래에 사용될 수 있기 위해서 더 노력해 보겠습니다.
로그(Log)와 메트릭(Metric)의 차이점
먼저 모니터링 시스템 아키텍처 구현전에 로그와 메트릭의 차이점에 대해 설명하자면 로그는 문제의 원인을 파악하는 것에 중점을 둔 데이터고 메트릭은 성능 및 상태 모니터링에 중점을 둔 데이터를 의미합니다. 예를 들어 API 요청과 응답, 에러 메시지, 시스템 자체 발생 이벤트 등은 로그성 데이터고, CPU 사용률, 메모리 사용량, API 응답 시간등은 메트릭성 데이터라고 할 수 있습니다.
즉, 로그로 디버깅하고 메트릭을 통해 성능과 상태를 추적함으로써 로그 모니터링 시스템에서 각 데이터가 상호보완적으로 역할을 수행할 수 있습니다.
모니터링 시스템 설계
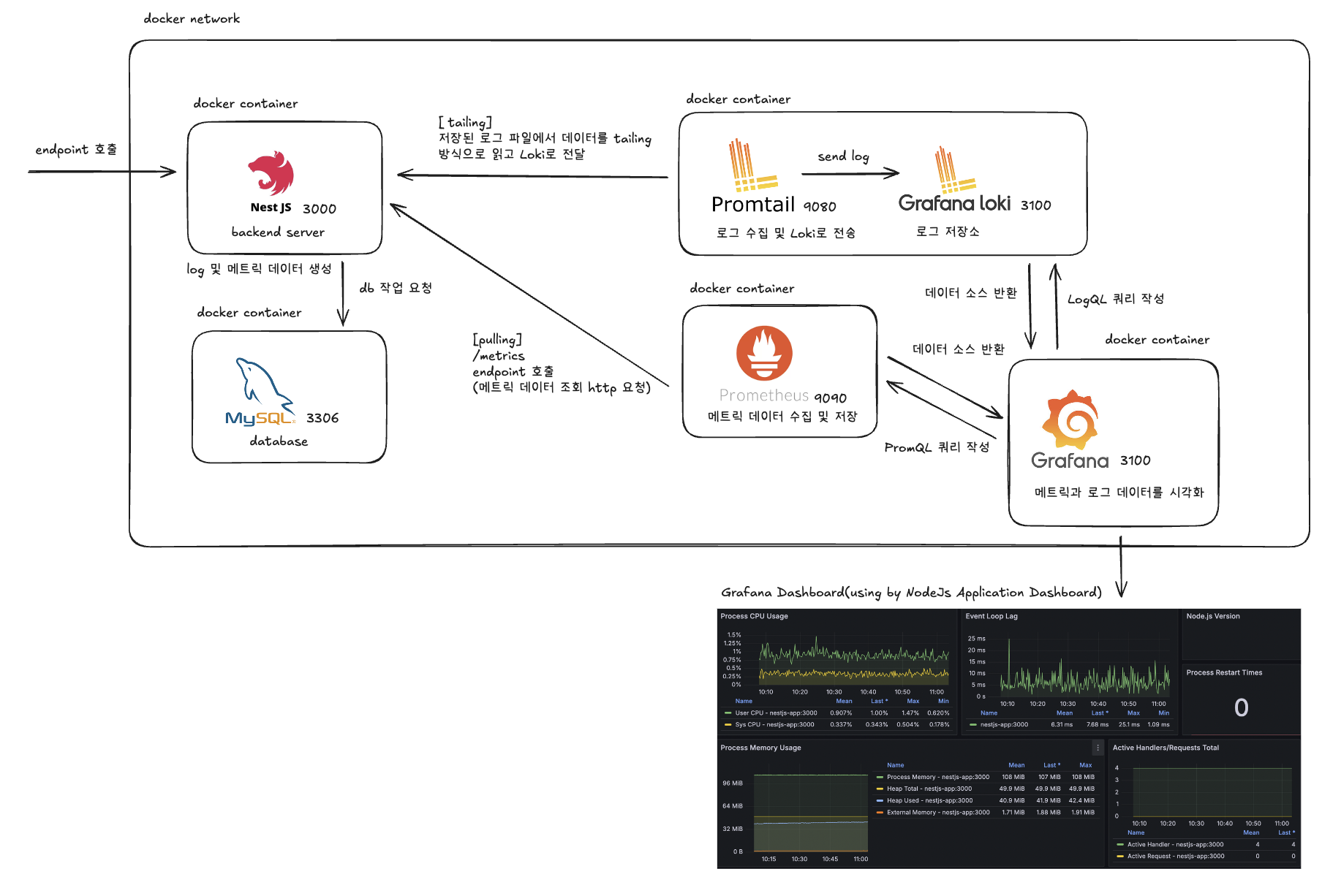
모니터링 시스템을 설계하기 위해 사용된 기술과 각각의 역할 및 상호작용 방법에 대해 정리하자면 다음과 같습니다.
- NestJs Framework
- Mysql
- Grafana
- Prometues
- Loki
- Promtail
- Docker
Loki (Log Aggregation)
Loki는 로그 집합 시스템으로 애플리케이션과 인프라의 로그를 저장하고 조회 하는 데 사용됩니다. 전통적인 데이터베이스와는 다르게 Loki는 로그의 메타데이터만 인덱싱 하고 있습니다.
예를 들어 다음과 같은 로그 라인이 있다고 가정했을 때 이 로그 라인은 아래 레이블을 가질 수 있습니다. 이러한 레이블을 사용해서 로그를 그룹화하면 특정 애플리케이션의 production환경에서 발생한 에러 로그를 쉽게 조회할 수 있습니다.
- app="webserver"
- env="production"
- level="error"
{"app": "webserver", "env": "production", "level": "error"} 2025-01-12 12:00:00 Error occurred in webserver application.
Promtail (Log Forwarder)
Loki는 로그를 저장할 때 최소한의 인덱싱만 수행하고, 메타데이터(라벨 기반)로 검색을 최적화합니다. 주로 Loki는 Promtail을 사용해서 로그 파일을 모니터링하고 메타데이터(예. 파일 이름, 호스트 정보)를 추가한 뒤 Loki로 전송하게 되는데 이 구조는 Loki 자체가 로그 파일을 직접 읽는 복잡성을 줄이고 Promtail이 데이터를 사전 처리 하도록 책임과 역할이 명확히 분리됐다고 볼 수 있습니다.
번외로, Loki는 Fluentd, Logstash, Filebeat 등 도구들과 통합될 수 있는데 모든 환경에서 자체적으로 로그를 수집하려면 Loki가 여러 로그 형식을 지원해하며 이는 유지 보수와 확장성을 떨어뜨릴 수 있습니다. 때문에 Loki는 저장 및 검색에 집중하고 수집은 Promtail에 맡기는 것입니다.
Promtail은 서버나 컨테이너에서 생성되는 로그 파일을 실시간으로 모니터링합니다. 새로운 로그 항목이 추가되면 이를 감지해서 Loki로 전송하는데 이 과정에서 'Tailing'방식을 사용합니다. 즉, 로그 파일을 직접 읽는 것이 아니라 파일의 끝부분을 실시간으로 모니터링하는 방법을 사용해서 로그가 변경됐는지를 모니터링 하고 추가된 내용이 있다면 Loki로 로그를 전송합니다.
Prometheus (Metrics Monitoring)
Loki가 로그성 데이터를 다룬다면, Prometheus는 메트릭성 데이터인 애플리케이션과 시스템 성능 지표를 수집하고 시계열 데이터를 저장하는 역할을 담당합니다.
Prometheus는 Loki와 다르게 자체적으로 데이터를 수집합니다. 그 이유는 메트릭은 대부분 표준화된 HTTP 엔드포인트를 통해 제공되며 Prometheus는 이를 직접 스크래핑합니다. 즉, 데이터를 가져오는 구조가 단순하고 일관적이므로 자체 수집이 가능하기 때문입니다.
또한 로그와 메트릭의 본질적인 차이 때문이기도 한데 로그는 비정형 데이터로 소스별 형식이 다양하고 수집 및 가공이 필요하다는 특징이 있지만, 메트릭은 정형 데이터로 고정된 구조를 가지며 간단히 수집 가능하다는 특징 때문에 Prometheus는 별도의 포워더 없이 직접 데이터를 스크래핑할 수 있습니다.
Prometheus는 Promtail과 비교했을 때 메트릭 데이터를 수집하는 방식이 다릅니다. Prometheus는 주로 'Pulling' 방식을 사용해서 메트릭 데이터를 수집하는데 이는 Prometheus 서버가 주기적으로 대상 시스템에서 데이터를 주기적으로 요청하여 가져오는 것을 의미합니다.
Grafana (Visualization and Monitoring Dashboard)
마지막으로 그라파나는 Loki와 Prometheus에서 수집한 데이터를 사용자에게 시각적으로 보여주는 역할을 담당합니다. Loki의 로그 데이터와 Prometheus의 메트릭 데이터를 통합하는 것이 가능하고 다양한 시각화 유형(그래프, 테이블 등)을 지원하고 있습니다.

서버 간 상호작용을 다시 보자면 다음과 같습니다.
- Promtail -> Loki: Promtail이 로그 데이터를 수집해서 Loki에 전달합니다.
- Prometheus -> Grafana: Prometheus가 수집한 메트릭 데이터를 그라파나에 제공합니다.
- Loki -> Grafana: Loki에서 수집된 로그 데이터를 그라파나가 시각화합니다.


코드 실습 (NestJS + Docker를 활용한 모니터링 시스템 구축 예시)
이제 본격적으로 NestJs를 활용한 모니터링 시스템을 구축하기 위한 환경 세팅 및 코드 예시입니다.
├── Dockerfile.dev
├── docker-compose.yml
├── logs
│ └── app.log
├── loki
│ └── local-config.yaml
├── nest-cli.json
├── package.json
├── prometheus
│ └── prometheus.yml
├── promtail
│ └── promtail-config.yml
├── promtail-config.yaml
├── src
│ ├── app.controller.spec.ts
│ ├── app.controller.ts
│ ├── app.module.ts
│ ├── app.service.ts
│ ├── board
│ ├── common
│ ├── datasource.initializer.ts
│ └── main.ts
├── tsconfig.build.json
├── tsconfig.json
└── yarn.lock
Loki 세팅
먼저 Loki를 사용해서 로그를 저장하고 처리하는 방식에 대한 설정을 진행합니다.
# /loki/local-config.yaml
# Loki를 파일 시스템을 백엔드로 사용하여 배포하는 완전한 구성입니다.
# 인덱스는 tsdb-shipper를 통해 스토리지로 전송됩니다.
auth_enabled: false # 인증을 사용하지 않도록 설정
server:
http_listen_port: 3100 # Loki 서버가 수신할 HTTP 포트 설정 (기본값: 3100)
common:
ring:
instance_addr: 127.0.0.1 # Loki 인스턴스의 주소 (클러스터링을 위한 주소 설정)
kvstore:
store: inmemory # 키-값 스토어 설정 (여기서는 메모리 내에서 관리)
replication_factor: 1 # 복제 인스턴스 수 (기본값: 1)
path_prefix: /tmp/loki # Loki의 기본 경로 설정 (데이터를 저장할 디렉터리 경로)
schema_config:
configs:
- from: 2020-05-15 # 스키마 버전 시작일 설정 (이 날짜 이후부터 적용)
store: tsdb # 저장소 유형 (TSDB 사용)
object_store: filesystem # 객체 스토어 유형 (파일 시스템 사용)
schema: v13 # 스키마 버전 설정
index:
prefix: index_ # 인덱스 파일의 접두사 (기본값: 'index_')
period: 24h # 인덱스 생성 주기 설정 (24시간마다 새로운 인덱스를 생성)
storage_config:
filesystem:
directory: /tmp/loki/chunks # 파일 시스템에 저장할 로그 청크 디렉터리 경로 설정
limits_config:
ingestion_rate_mb: 10 # 초당 최대 수집 속도 (기본값: 4MB, 이 값을 10MB로 설정)
ingestion_burst_size_mb: 20 # 버스트 모드에서 최대 수집량 (기본값: 6MB, 이 값을 20MB로 설정)
per_stream_rate_limit: 5MB # 스트림 당 최대 수집 속도 (기본값: 3MB, 이 값을 5MB로 설정)
per_stream_rate_limit_burst: 10MB # 스트림 당 버스트 모드에서 최대 수집량 (기본값: 15MB, 이 값을 10MB로 설정)
Loki의 기본 구조는 로그 데이터를 TSDB(Time Series Database) 형태로 저장합니다. 해당 데이터베이스는 기본적으로 두 가지 중요한 요소를 갖습니다.
- 로그 청크(Log Chunks): 실제 로그 메시지들이 저장되는 파일
- 인덱스(Index): 로그 데이터를 효율적으로 검색할 수 있도록 돕는 메타 데이터
/loki/local-config.yml 파일에서 몇 가지 중요한 설정은 storage_config에서 filesystem 옵션에 따라 로그 청크는 지정된 디렉토리(/tmp/loki/chunks)에 저장되게 하고, 인덱스는 24h 마다 새로 생성되도록 합니다.
추가적으로 tsdb-shipper는 Loki의 인덱스를 외부 스토리지로 전송하는 설정을 의미하는데 Loki가 로그 데이털르 디스크에 저장할 때 인덱스 데이터를 filesystem이 아닌 외부 스토리지(예, S3, GCS)에 보관하면 tsdb-shipper가 인덱스를 외부 저장소로 옮길 수 있습니다.
Promtail 세팅
# 서버 관련 설정
server:
http_listen_port: 9080 # Promtail HTTP 서버가 수신할 포트 설정
grpc_listen_port: 0 # gRPC 서버 포트를 사용하지 않도록 설정 (0은 비활성화)
# 로그 위치 정보 기록을 위한 설정
positions:
filename: /tmp/positions.yaml # 마지막으로 처리된 로그 위치를 저장할 파일 경로
# Loki 서버에 로그를 전송하는 클라이언트 설정
clients:
- url: http://loki:3100/loki/api/v1/push # Loki 서버의 URL (로그를 전송할 주소)
batchwait: 1s # 로그를 전송하기 전에 대기하는 시간 (기본값: 1s)
batchsize: 1048576 # 한 번에 전송하는 최대 바이트 수 (기본값: 1MB, 즉 1,048,576 bytes)
# 로그 수집 설정
scrape_configs:
- job_name: docker # 수집 작업의 이름 (docker-logs로 명명됨)
static_configs:
- targets:
- localhost # 수집 대상이 되는 호스트 (여기서는 localhost)
labels:
job: docker-logs # 'docker-logs'라는 레이블을 지정하여 수집 작업을 구분
__path__: /var/lib/docker/containers/*/*.log # Docker 컨테이너의 로그 파일 경로
- job_name: docker # 두 번째 수집 작업, Docker 컨테이너의 메타데이터를 활용하여 로그 수집
docker_sd_configs:
- host: unix:///var/run/docker.sock # Docker 소켓을 통해 Docker 메타데이터에 접근
relabel_configs:
- source_labels: [__meta_docker_container_name] # Docker 컨테이너 이름을 기반으로 레이블 추가
target_label: container # 'container'라는 레이블을 지정하여 컨테이너 이름을 저장
- source_labels: [__meta_docker_container_name]
regex: '/(.*)' # 정규식을 사용하여 컨테이너 이름을 처리
replacement: '$1' # 처리된 컨테이너 이름을 레이블로 사용
target_label: container_name # 'container_name' 레이블로 컨테이너 이름 저장
이 설정 파일은 도커 환경에서 실행되는 애플리케이션의 로그를 수집하고 수집한 로그를 Loki로 전송하는 설정입니다.
이전에 Loki는 레이블을 기반으로 로그를 식별하고 분류한다고 했는데 해당 설정에서는 여러 레이블이 사용되고 있습니다.
- job: docker-logs: Docker 컨테이너의 로그를 수집함.
- __path__: /var/lib/docker/containers/*/*.log: scrape_configs에서 로그 파일 경로를 정의하면 해당 경로에 있는 로그 파일을 수집 대상으로 지정함.
- container_name: 로그를 Docker Container 별로 구분할 수 있게 해 줌.
Prometheus 설정
# global 설정은 모든 스크래핑 작업에 대한 기본값을 정의합니다.
global:
scrape_interval: 15s # 15초마다 데이터를 스크랩(수집)하도록 설정
# scrape_configs는 실제로 데이터를 스크랩할 대상을 정의합니다.
scrape_configs:
- job_name: 'nestjs-app' # 수집 작업의 이름. 예: 'nestjs-app'이라는 이름을 가진 작업
static_configs:
- targets: ['nestjs-app:3000'] # 'nestjs-app'이라는 호스트에서 3000 포트를 통해 메트릭을 수집
이 설정은 미리 정의된 NestJs 애플리케이션의 /metrics 엔드포인트를 pulling 방식으로 계속 호출하면서 메트릭 데이터를 수집하기 위한 설정입니다.
NestJs Framework 의존성 주입
# app.module.ts
@Module({
imports: [
... # typeorm 세팅
WinstonModule.forRoot({
transports: [
new winston.transports.Console({
format: winston.format.combine(
winston.format.timestamp(),
winston.format.json(),
),
}),
new LokiTransport({
host: 'http://localhost:3100', // Loki 서버의 URL
labels: { app: 'nestjs-app' }, // 로그 라벨 설정
}),
],
}),
PrometheusModule.register({
path: '/metrics', // Endpoint for Prometheus to scrape
defaultMetrics: {
enabled: true,
},
}),
...
],
controllers: [AppController],
providers: [AppService, DataSourceInitializer],
})
export class AppModule {}
먼저 NestJS 애플리케이션에서 Winston을 활용한 로깅 시스템을 설정하고, Loki와 Prometheus와의 통합을 포함하는 설정입니다.
- Winston 로깅 설정: Winston은 다양한 로그 대상에 로그를 기록할 수 있는 로깅 라이브러리로 여기서는 두 가지 전송 방식을 설정합니다.
- 콘솔 로그: Console에 로그가 출력됩니다.
- Loki로 전송: Loki에 저장될 로그의 레이블을 설정합니다.
- Prometheus 모니터링 설정: Prometheus는 주기적으로 /metrics 엔드포인트를 스크랩해서 애플리케이션 메트릭을 수집합니다. (/src/common/metrics/metrics.controller.ts, metrics.service.ts 파일 참고)
async function bootstrap() {
initializeTransactionalContext();
const app = await NestFactory.create(AppModule); // AppModule에서 설정한 로거가 자동으로 사용됨
app.useGlobalInterceptors(new LoggingInterceptor()); // 전역 로깅 인터셉터 설정
await app.listen(3000, '0.0.0.0');
}
bootstrap();
해당 설계에서는 Http Request, Response에 대한 로그를 항상 기록하기 위해서 Interceptor를 추가했습니다.
// logging.interceptor.ts
@Injectable()
export class LoggingInterceptor implements NestInterceptor {
intercept(context: ExecutionContext, next: CallHandler): Observable<any> {
const request = context.switchToHttp().getRequest();
const now = Date.now();
// 특정 경로를 로깅에서 제외
if (request.url === '/metrics') {
return next.handle();
}
// 요청 로깅: 메서드, URL, 헤더, 파라미터, 본문
logger.info(`Incoming request: ${request.method} ${request.url}`);
logger.info(`Headers: ${JSON.stringify(request.headers)}`);
logger.info(`Params: ${JSON.stringify(request.params)}`);
logger.info(`Query: ${JSON.stringify(request.query)}`);
logger.info(`Body: ${JSON.stringify(request.body)}`);
return next
.handle()
.pipe(
tap((response) => {
// 응답 로깅: 상태 코드, 응답 본문, 처리 시간
const responseTime = Date.now() - now;
logger.info(`Outgoing response: ${request.method} ${request.url} ${response.statusCode} ${responseTime}ms`);
logger.info(`Response body: ${JSON.stringify(response)}`);
}),
catchError((err) => {
// 오류 로깅: 상태 코드, 오류 메시지, 처리 시간
const responseTime = Date.now() - now;
logger.error(`Error response: ${request.method} ${request.url} ${err.status} ${responseTime}ms`);
logger.error(`Error details: ${JSON.stringify(err.response)}`);
throw err;
}),
);
}
}
추가로 /src/common/logger/typeorm-logger.service 파일을 참고하면(모든 소스는 github에 올려뒀습니다.) typeorm과 관련된 로그를 수집하고 조회할 수 있도록 별도의 파일을 생성했습니다.
마지막으로 docker compose를 활용해서 모든 서버를 띄워줍니다.
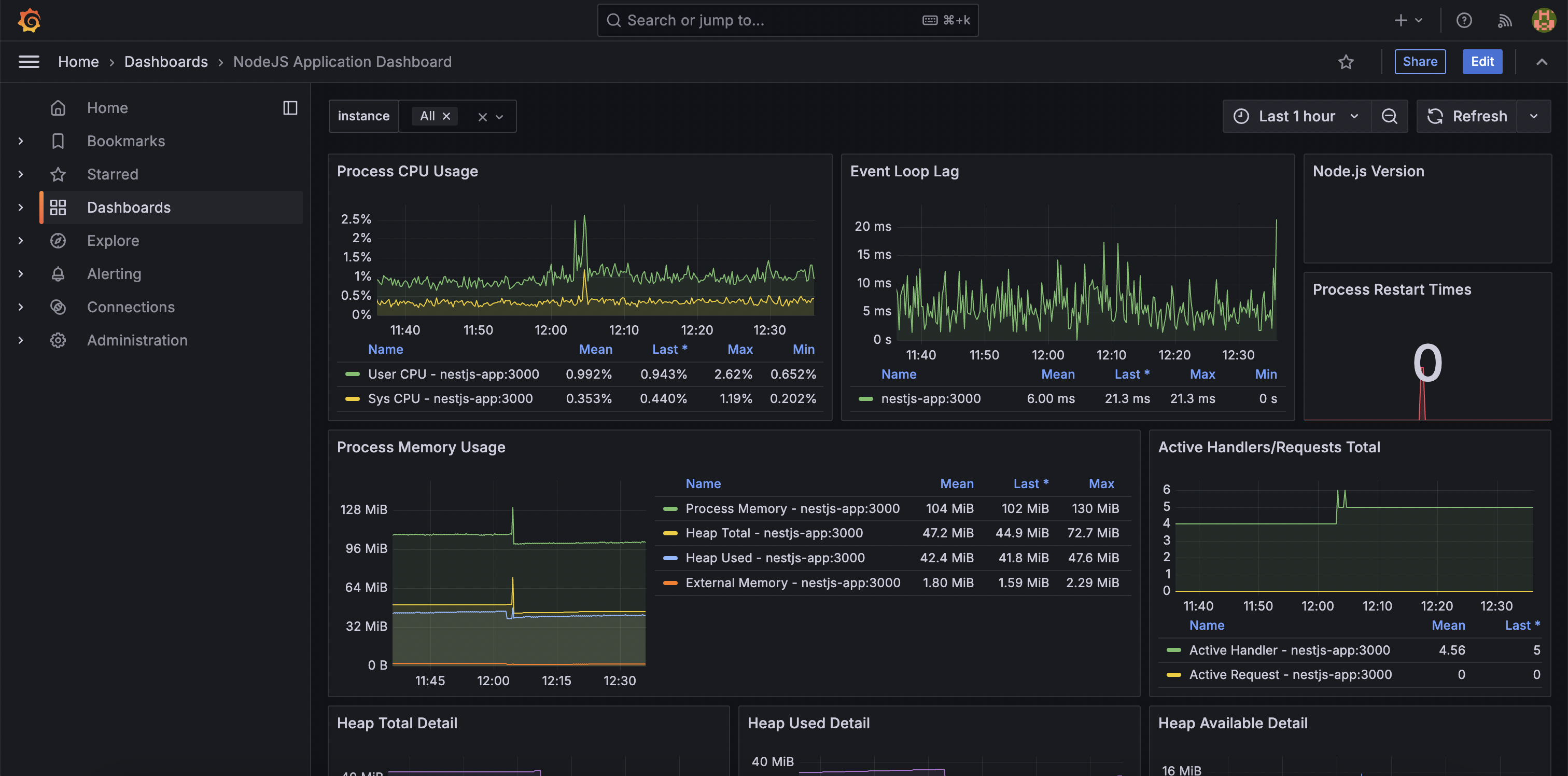
Loki, Prometheus Monitoring
먼저 http://localhost:3001/로 접속하면 Grafana에 접속할 수 있습니다. (아이디 비번은 admin으로 초기화되어 있습니다.)
/home/explore 메뉴로 들어가서 'Configure a new data source'를 선택합니다.
추가할 datasource에 Loki, Promethus를 각각 선택하고 (한 번에 하나씩) Connection 할 url을 작성합니다. 도커 컨테이너명:port 형식으로 입력해 주시면 준비는 완료입니다.
그럼 아래처럼 Datasource가 추가된 것을 확인하실 수 있습니다.

Loki, Prometheus는 각각 LogQL, PromQL이라는 Query Lanaguage를 사용해서 데이터를 조회할 수 있습니다. 그라파나는 쿼리를 직접 작성해서 Loki, Prometheus 각각 로그와 메트릭 데이터를 조회할 수 있습니다.
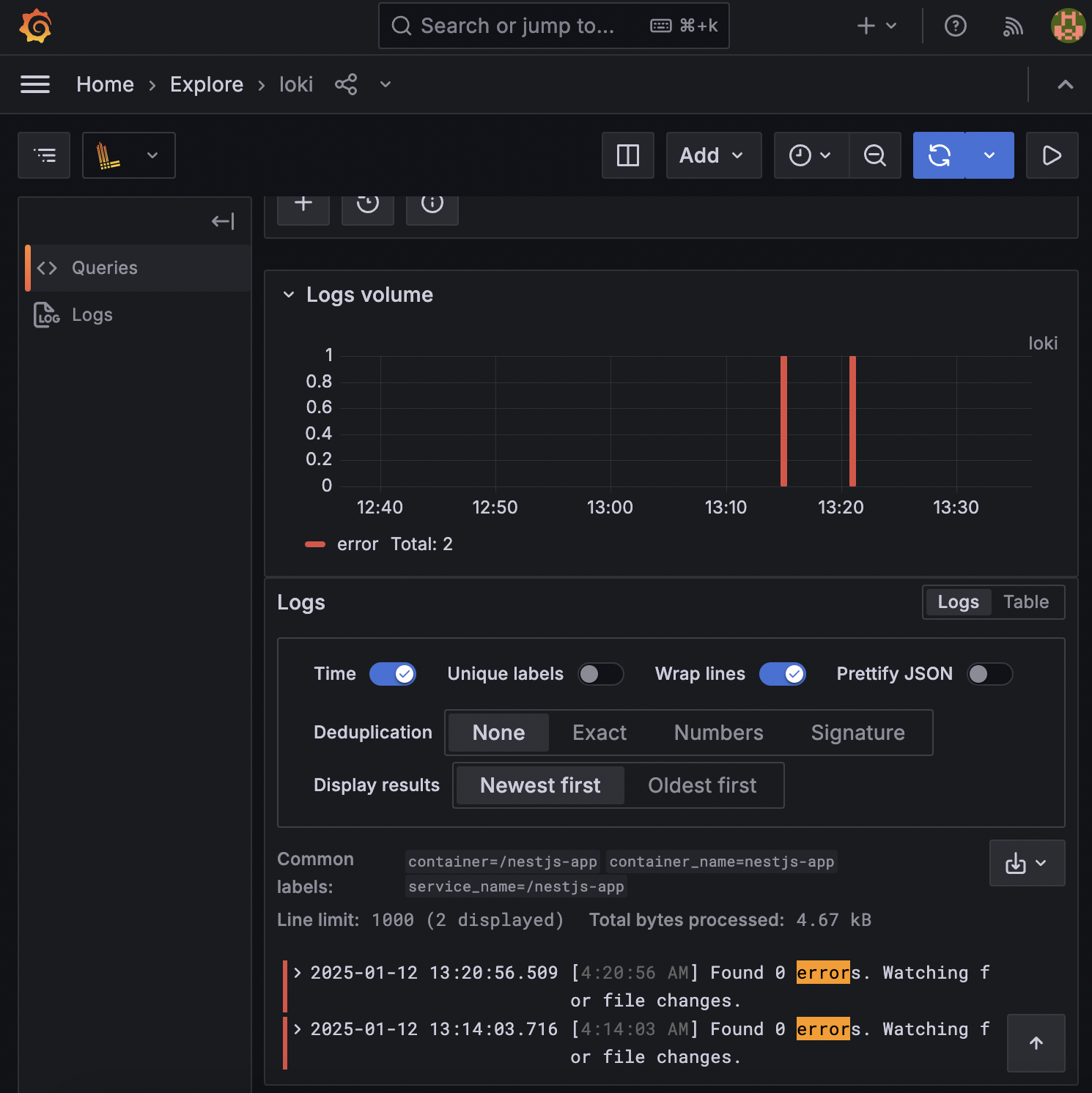
마무리
현재 1년간 개발을 하면서 디버깅을 위한 별도의 모니터링 시스템이 구축되어 있지 않아 오류가 생겼을 때 Sentry에서 로그성 데이터를 확인하거나 상황을 직접 재현하는 방식 외에는 문제를 인지하고 해결하기까지 많은 시간이 소요됐던 것 같습니다.
이번에 로그, 메트릭 모니터링 시스템을 혼자 구축해 보면서 모니터링 시스템의 동작 원리를 이해할 수 있었고 사내에서 공유되어 사용될 수 있다면 좋겠다는 생각이 들었습니다.
'Framework > NestJS' 카테고리의 다른 글
| NestJS의 Provider vs Spring의 Component: 등록 및 관리 방식의 핵심 차이 및 분석 (1) | 2025.03.23 |
|---|---|
| NestJs는 AOP를 지원할까? Spring AOP와의 비교 분석 (0) | 2025.03.03 |
| NestJS Guards Authentication with Passport (0) | 2025.03.02 |
| NestJS Request lifecycle (0) | 2025.03.02 |
| TypeORM QueryRunner vs @Transactional (0) | 2025.01.05 |