이전에 작성한 마이크로서비스 아키텍처에 대한 내용에서 언급했듯이 마이크로서비스는 기존의 모놀리식 환경과는 다른 문제점들을 해결하기 위해서 몇 가지 디자인 패턴이 있다고 소개했었습니다. 자세한 내용은 아래 링크를 참고해 주세요.
마이크로서비스 아키텍처(MSA) 란?
개요현재 이커머스 B2B 솔루션 서비스를 제공하고 있는 회사에 재직 중에 사내에서 기존의 레거시 시스템을 MSA로 구축을 위한 움직임을 조금씩 보이고 있는 것 같아 그 변화에 합류하기 위해 MSA
jminc00.tistory.com
이번 포스팅은 '마이크로서비스 디자인 패턴' 들 중 서비스 검색(Service Discovery)이라는 주제에 대해 학습하고 실습한 내용을 공유해 볼 예정입니다.
서비스 검색(Service Discovery) 란 무엇이며, 왜 필요한가?
먼저 서비스 검색은 왜 필요한가? 에 대한 빌드업 과정이 필요합니다. 모놀리식 아키텍처와 비교했을 때 MSA가 갖는 가장 큰 장점은 '각 서비스의 독립적 개발, 테스트, 배포가 가능하다'는 점입니다.
예를 들어 주문 서비스에 대한 수요가 증가해 처리 성능을 위해 서버 스케일을 확장해야 한다는 니즈가 있을 수 있습니다. 실제로 현재 재직 중인 회사에서는 특정 고객사의 '주문'이 타 고객사에 비해 월등히 많은 경우가 있었습니다. 회사에서는 판매처의 주문을 수집하고 내부 서버에서 전처리하는 과정 등 주문과 관련된 서비스의 부하가 너무 커져서 다른 고객사들의 속도에 영향을 미치는 사례가 있었습니다. 해당 케이스에서는 특정 고객사의 주문을 처리하는 물리적 서버를 별도로 분리하는 방법으로 문제를 해결했습니다. 만약 마이크로서비스 환경이었다면 주문 서비스의 스케일을 확장해서 문제를 해결할 수도 있었을 거라고 생각합니다.
마이크로서비스 환경에서 각 서비스를 독립적으로 개발 테스트, 배포가 가능하다는 점은 바꿔 말하면 해당 서비스만 독립적으로 확장이 가능하다는 것을 의미합니다. (독립적 확장의 가능함은 개발의 비용을 줄이고 운영의 효율성을 크게 향상할 수 있다고 생각합니다.)
일반적으로 MSA는 클라우드 환경에서 운영한다고 합니다. 그 이유는 다음과 같습니다.
- 확장성 : 클라우드 인프라는 필요에 따라 리소스를 동적으로 할당하거나 축소하기에 용이합니다.
- 자원효율성 : 필요한 만큼의 리소스를 사용하고 비용을 지불합니다.
- 자동화와 관리 효율성 : 자동화 관리 도구를 지원하며 모니터링, 배포, 로깅 등의 작업을 지원합니다.
이번 포스팅의 주제인 서비스 검색은 '확장성'과 밀접한 관련이 있습니다. 앞선 예시에서 봤듯이 특정 서비스의 스케일업이 필요한 경우 클라우드에서 운영 중인 특정 마이크로서비스의 인스턴스의 수를 늘림으로써 스케일업을 할 수 있습니다. (스케일업의 방법은 서버의 처리 성능을 높이는 방법과 물리적 서버의 수를 늘리는 방법 등이 존재하는데 해당 케이스는 후자에 해당합니다.)
이런 경우 클라우드에 올라가는 인스턴스는 네트워크 위치가 동적으로 생성이 되는 경우가 많습니다. 즉, 인스턴스의 추가나 삭제, 오토스케일링의 이유로 IP 가 동적으로 변할 수 있음을 의미합니다. 때문에 MSA에서는 동적으로 변하는 인스턴스의 IP를 추적하기 위해서 서비스 검색이 필요합니다.
그렇다면 서비스 검색(Service Discovery)란 무엇일까요? 서비스 검색이란 마이크로서비스 아키텍처에서 각 서비스의 위치(IP 주소와 포트)를 동적으로 발견하고 관리하는 메커니즘을 의미합니다. 쉽게 말하면 클라이언트는 서비스 검색 메커니즘을 통해 어떤 서버의 인스턴스로 처리 요청을 보낼지를 결정하는 것이 가능합니다.
Spring Cloud Eureka로 서비스 검색 구현하기 (준비)
서비스 검색이 마이크로서비스 환경에서 필요한다는 것이 어느 정도 이해가 됐다면, 이제는 어떻게 서비스 검색을 구현할 수 있을지 궁금할 것입니다. 이 포스팅은 '스프링으로 하는 마이크로서비스 구축' 책을 통해서 배운 내용과 기타 레퍼런스를 통해 추가 학습한 내용들을 정리했기 때문에 스프링을 통해 마이크로서비스 환경에서 서비스 검색을 어떻게 구현할지에 대해 정리해보려고 합니다.
먼저 스프링 프레임워크는 마이크로서비스 아키텍처를 위해 스프링 클라우드(Spring Cloud)라는 기술을 지원하고 있습니다. 이 중에서 Spring Cloud Eureka는 서비스 검색을 구현하기 위해 지원하는 기술입니다.
Spring Cloud Eureka는 Netflix Eureka를 기반으로 두고 있습니다. Netflix Eureka는 넷플릭스가 개발한 오픈소스 프로젝트로 자체적으로 실행되는 서비스 검색 서버입니다. 다만, Netflix Eureka는 스프링 클라우드와 같은 프레임워크와의 통합이 기본적으로 제공되지 않기 때문에 통합을 위한 추가적인 설정이 필요합니다. 이런 복잡한 설정 과정을 생략하고 스프링 프레임워크와 통합을 지원하는 Spring Cloud Eureka를 사용하는 것을 추천드립니다.
서비스 검색을 구현하는 종류는 두 가지가 있습니다.
- 클라이언트 사이드 서비스 검색(Client-Side Service Discovery)
- 서버 사이드 서비스 검색(Server-Side Service Discovery)
이번 포스팅에서 구현할 서비스 검색 구현 방법은 클라이언트 사이드 방식입니다. 클라이언트 사이드 방식은 클라이언트가 서비스 레지스트리로부터 서비스 인스턴스 목록을 가져와서 직접 부하 분산을 처리하는 방법을 의미합니다. 단어들에 대한 보충설명은 아래에서 구현하는 과정에서 한번 더 언급하겠습니다.
아래 이미지는 이제부터 구현하게 될 마이크로서비스 환경에서 서비스 검색을 구현하기 위한 아키텍처 설계 이미지 예시입니다. 아키텍처의 구성요소에 대해 하나하나 알아보겠습니다.
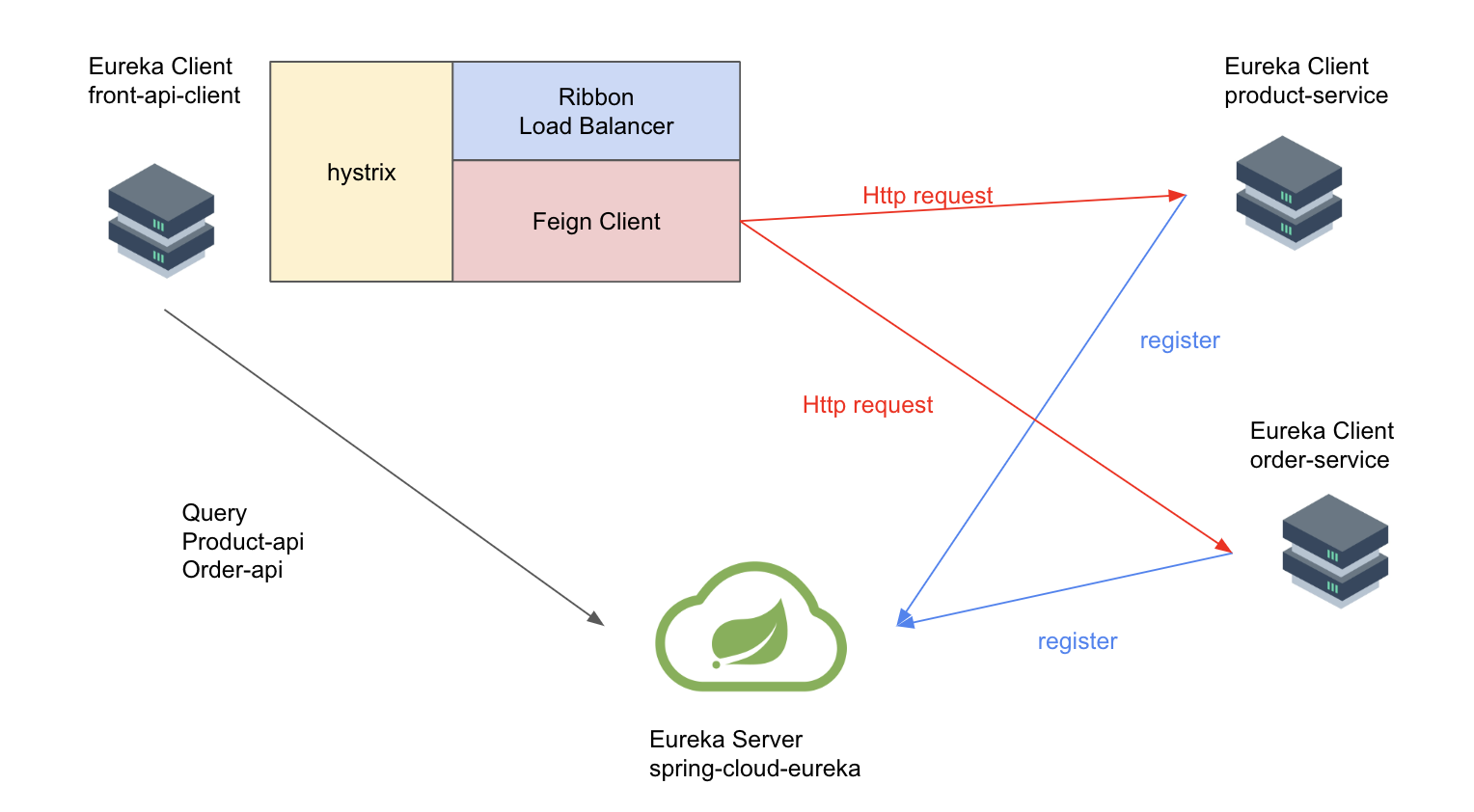
먼저 가장 왼쪽의 front-api-client는 각 마이크로서비스의 엔드포인트를 호출하게 될 client 역할을 담당합니다. 중요한 점은 해당 아키텍처가 클라이언트 사이드 서비스 검색 패턴이라는 것입니다. 즉, 클라이언트가 직접 로드 밸런싱을 한다는 뜻입니다. 그게 어떻게 가능한지 알기 위해서는 그 옆에 그려져 있는 hystirx, ribbon, feign client에 대해 알아야 합니다.
먼저 Netflix Hystrix는 MSA에 서킷 브레이커 패턴을 구현한 기술입니다. Hystrix는 영어로 '고슴도치'라는 뜻으로 고슴도치가 가시를 사용해서 외부의 위협으로부터 자신을 지키는 것처럼 Netflix Hystrix는 MSA가 장애로부터 보호한다는 것을 의미합니다. 서킷 브레이커 패턴(Circuit Breaker Pattern)이란, 시스템에서 장애를 방지하고 복구 시간을 줄이기 위해 사용되는 디자인 패턴으로, 전기 회로에서 과부하 등과 같은 상황을 방지하기 위해 사용하는 서킷 브레이커와 비슷한 개념입니다. 간단히 말하자면, 시스템의 한 부분에서 발생한 장애가 다른 부분으로 전파되지 않도록 방지하는 디자인 패턴입니다.
다음은 Ribbon Load Balancer입니다. Netflix Ribbon은 클라이언트 사이드 로드 밸런서 기능을 제공하는 기술입니다. 즉, 클라이언트 요청을 여러 서비스 인스턴스에 분산시켜 부하를 고르게 분배하는 역할을 담당합니다. Netflix Ribbon는 유레카와 같은 서비스 검색 시스템에서 동적으로 사용 가능한 서버 목록을 검색하고 특정 조건에 맞는 서버로 요청을 전송합니다.
마지막은 Feign Client입니다. Feign 은 영어로 '가장하다'라는 뜻으로 Feign을 사용하면 인터페이스를 통해 http 요청을 선언적으로 정의할 수 있습니다. Feign 은 MSA에서 서비스 간의 통신을 추상화하는데 유용하게 사용됩니다.
즉, Netflix Hystrix는 서킷 브레이커 패턴을 제공해 장애 복원력을 강화하고, Ribbon Load Balancer는 클라이언트 사이드 로드 밸런싱 기능을 지원하며, Feign Client는 인터페이스를 통한 HTTP 요청 추상화를 가능하게 하여, 마이크로서비스 아키텍처에서 이 세 가지를 통합하여 사용하면 서비스 호출의 안정성, 부하 분산, 코드의 간결성을 동시에 달성할 수 있습니다.
마지막으로, Eureka Client인 product-service와 order-service는 각각 Eureka 서버에 클라이언트로 등록됩니다. 각 마이크로서비스가 스케일링되어 인스턴스 수가 증가하거나 감소할 때, Eureka는 이를 즉시 감지하고 레지스트리에 반영합니다.
유레카가 각 마이크로서비스의 인스턴스 수의 변화를 즉시 감지할 수 있는 이유는 (유레카) 클라이언트가 주기적으로 자신의 상태를 유레카 서버에 보고하기 때문입니다. 이 방식을 heartbeat 메커니즘이라고 부릅니다. heartbeat 메커니즘은 클라이언트가 주기적으로 자신이 여전히 살아있고, 서비스가 정상적으로 동작하고 있음을 유레커 서버에 알립니다. heartbeat 메커니즘의 작동원리는 다음과 같습니다.
- 등록 및 주기적 보고
- 클라이언트는 유레카 서버에 자신의 정보를 등록하고, 등록 후 일정 시간 간격으로 서버에 자신의 상태를 주기적으로 보고합니다.
- 클라이언트의 상태보고
- 클라이언트는 http 요청을 사용해 유레카 서버에 자신의 상태를 알려줍니다. 이 요청에 클라이언트의 현재상태, 위치, 메타데이터 등이 포함됩니다.
- 서버의 상태 확인
- 유레카 서버는 클라이언트로부터 밭은 heartbeat 요청을 기반으로 서비스의 상태를 갱신합니다. 주기적인 heartbeat 보고가 없거나 클라이언트로부터의 응답이 없으면 유레카 서버는 해당 인스턴스가 죽었다고 판단하고 레지스트리에서 제거합니다
먼저 유레카 서버에 대한 설정 정보입니다. build.gradle에 Eureka-server와 관련된 의존성을 추가합니다.
ext {
set('springCloudVersion', '2021.0.3')
}
dependencies {
implementation 'org.springframework.cloud:spring-cloud-starter-netflix-eureka-server'
...
}
dependencyManagement {
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${springCloudVersion}"
}
}다음은 application.yml 설정 파일을 수정합니다.
server:
port: 8761
eureka:
instance:
hostname: localhost
client:
registerWithEureka: false
fetchRegistry: false
serviceUrl:
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
server:
waitTimeInMsWhenSyncEmpty: 0
response-cache-update-interval-ms: 5000- eureka.instance.hostname: Eureka 서버 인스턴스의 호스트명을 설정합니다.
- eureka.client.registerWithEureka: Eureka 서버가 자신을 Eureka 서버 레지스트리에 등록할지 여부를 설정합니다. false로 설정되어 있으므로, 이 서버는 자신을 Eureka 서버 레지스트리에 등록하지 않습니다. 즉, 이 서버는 클라이언트로서 작동하지 않고, 오직 Eureka 서버 역할만 합니다.
- eureka.client.fetchRegistry: 클라이언트가 Eureka 서버에서 다른 서비스의 레지스트리를 가져올지 여부를 설정합니다. false로 설정되어 있으므로, 이 서버는 다른 서비스의 레지스트리를 가져오지 않습니다.
- eureka.client.serviceUrl.defaultZone: 이 URL은 Eureka 서버의 기본 URL을 나타냅니다.
- eureka.server.waitTimeInMsWhenSyncEmpty: Eureka 서버가 동기화 요청을 처리할 때, 동기화된 데이터가 비어있을 경우 기다릴 시간을 설정합니다. 0으로 설정되어 있어, 빈 동기화 요청에 대해 기다리지 않습니다.
- eureka.server.response-cache-update-interval-ms: Eureka 서버가 캐시 된 응답을 업데이트하는 간격을 밀리초 단위로 설정합니다. 5000으로 설정되어 있으므로, 캐시는 5초마다 업데이트됩니다.
@EnableEurekaServer
@SpringBootApplication
public class SpringCloudEurekaApplication {
public static void main(String[] args) {
SpringApplication.run(SpringCloudEurekaApplication.class, args);
}
} 마지막으로 @EnableEurekaServer 어노테이션을 사용해서 해당 애플리케이션을 유레카 서버로 활성화합니다. 여기까지가 유레카 서버에 대한 작업입니다.
다음은 각 마이크로서비스에 대한 내용을 보겠습니다. build.gradle에서 이전과 다른 점은 Eureka Client 관련 의존성을 추가했다는 점입니다.
ext {
set('springCloudVersion', '2021.0.3')
}
dependencies {
implementation 'org.springframework.cloud:spring-cloud-starter-netflix-eureka-client'
...
}
dependencyManagement {
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${springCloudVersion}"
}
}다음은 application.yml 파일의 설정 정보를 수정합니다.
server:
port: 8080
spring:
application:
name: order-service
eureka:
client:
serviceUrl:
defaultZone: http://eureka:8761/eureka/
initialInstanceInfoReplicationIntervalSeconds: 5
registryFetchIntervalSeconds: 5
instance:
leaseRenewalIntervalInSeconds: 5
leaseExpirationDurationInSeconds: 5가장 중요한 설정정보는 두가지 입니다.
- spring.application.name: 해당 설정정보는 Eureka 서버에 등록될 때 사용되며, 서비스의 식별자 역할을 합니다.
- eureka.client.serviceUrl.defaultZone: Eureka 서버의 URL을 설정합니다. 이 URL은 클라이언트가 Eureka 서버와 통신하는 주소를 지정합니다. http://eureka:8761/eureka/는 Eureka 서버의 주소를 나타내며, eureka는 DNS 이름 또는 호스트명이 될 수 있습니다. 이 설정은 클라이언트가 Eureka 서버에 등록하거나 정보를 가져오는 데 사용됩니다. 해당 실습에서는 호스트명이 'eureka'라고 되어있는데 이는 도커 컨테이너 이름입니다. 해당 실습은 도커 환경에서 진행했습니다.
그리고 각 마이크로서비스에서 간단한 endpoint 호출을 위한 Controller를 생성합니다. 나중에 Feign Client의 인터페이스에 의해 추상화될 HTTP 요청 endpoint입니다. ip 주소를 출력하는 이유는 나중에 각 인스턴스별로 로드밸런싱이 되는 것을 눈으로 확인하기 위합니다. order-service와 product-service의 설정 정보는 동일하기에 product-service는 생략하겠습니다.
import java.net.InetAddress;
import java.net.UnknownHostException;
@RestController
@RequestMapping("/api/v1")
public class OrderController {
@GetMapping("/order")
public String getOrder() {
try {
String ipAddress = InetAddress.getLocalHost().getHostAddress();
return "order:[" + ipAddress + "]";
} catch (UnknownHostException e) {
return "order:[Unable to determine IP address]";
}
}
}다음은 front-api-client 입니다. 먼저 build.gradle은 feign client와 유레카 클라이언트 관련 의존성을 추가합니다.
ext {
set('springCloudVersion', '2021.0.3') // Updated to a more recent version
}
dependencies {
implementation 'org.springframework.cloud:spring-cloud-starter-openfeign'
implementation 'org.springframework.cloud:spring-cloud-starter-netflix-eureka-client'
...
}
dependencyManagement {
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${springCloudVersion}"
}
}다음은 application.yml 파일의 설정관련 정보를 추가합니다.
server:
port: 8080
eureka:
client:
register-with-eureka: false
service-url:
defaultZone: http://eureka:8761/eureka/
order-service:
ribbon:
ConnectionTimeout: 500
ReadTimeout: 5000
product-service:
ribbon:
ConnectionTimeout: 500
ReadTimeout: 5000
feign:
hystrix:
enabled: true- ribbon.ConnectionTimeout: 클라이언트가 order-service,나 product-service의 서비스 인스턴스(서버)에 연결을 시도하고 서버와의 연결이 성립되지 않을 경우 기다릴 최대 시간을 설정합니다.
- ribbon.ReadTimeout: 클라이언트가 서버와의 연결이 성공적으로 성립된 후 응답을 기다리는 최대 시간을 의미합니다. 이 시간 동안 응답이 없으면 읽기를 중지하고 예외를 발생시킵니다.
- feign.hystrix.enabled: Feign Client에서 Hystrix를 활성화해서 서킷 브레이커 기능을 사용할 수 있도록 설정합니다.
다음은 @EnableFeignClients 어노테이션을 사용해서 Spring Cloud에서 Feign Client를 활성화합니다. 이 어노테이션은 Feign Client를 자동으로 스캔하고 이를 스프링의 ApplicationContext에 등록합니다. 그리고 Feign Client는 @FeignClient 어노테이션이 붙은 인터페이들을 정의합니다.
@EnableFeignClients
@SpringBootApplication
public class FrontApiClientApplication {
public static void main(String[] args) {
SpringApplication.run(FrontApiClientApplication.class, args);
}
}아래 코드처럼 @FeignClient 어노테이션을 자바 인터페이스 붙여서 Feign Client의 인터페이스 정의 목록에 등록합니다.
@FeignClient(name = "order-service")
public interface OrderFeignClient {
@GetMapping("/api/v1/order")
String getOrder();
}
그러면 아래 코드 처럼 Controller에 의해서 각 마이크로서비스의 Endpoint를 추상화해서 호출할 수 있습니다.
@RestController
@RequestMapping("/api/v1/order")
public class OrderController {
private final OrderFeignClient orderFeignClient;
public OrderController(OrderFeignClient orderFeignClient) {
this.orderFeignClient = orderFeignClient;
}
@GetMapping
public String getOrder() {
return this.orderFeignClient.getOrder();
}
}마지막은 docker-compose.yml 파일을 추가해 줍니다.(각 프로젝트별 Dockerfile은 생략하겠습니다.)
version: '2.1'
services:
eureka:
build: ./spring-cloud-eureka
mem_limit: 350m
ports:
- "8761:8761"
order-service:
build:
context: ./order-service
mem_limit: 350m
environment:
- EUREKA_CLIENT_SERVICEURL_DEFAULTZONE=http://eureka:8761/eureka/
depends_on:
eureka:
condition: service_started
product-service:
build:
context: ./product-service
mem_limit: 350m
environment:
- EUREKA_CLIENT_SERVICEURL_DEFAULTZONE=http://eureka:8761/eureka/
depends_on:
eureka:
condition: service_started
front-api-client:
build:
context: ./front-api-client
mem_limit: 350m
ports:
- "3000:8080"
environment:
- EUREKA_CLIENT_SERVICEURL_DEFAULTZONE=http://eureka:8761/eureka/
depends_on:
eureka:
condition: service_started 해당 파일에서 order-service, product-service는 직접 호출될 필요가 없어서 port 설정은 추가하지 않습니다. (port가 설정되어 있다면 현재로서는 docker compose 명령어로 스케일링하기 어렵습니다.)
이제 모든 작업이 마무리 됐으니 직접 실행해 보겠습니다. docker compose up을 하고 scale 정보를 추가합니다.
docker compose up --build -d --scale product-service=3
--scale product-service=3을 줘서 product-service 인스턴스를 3개를 유레카 서버 레지스트리에 등록합니다.
그럼 http://localhost:8731 경로로 접속하면 아래 이미지처럼 서비스의 instance가 등록됐음을 확인할 수 있습니다.
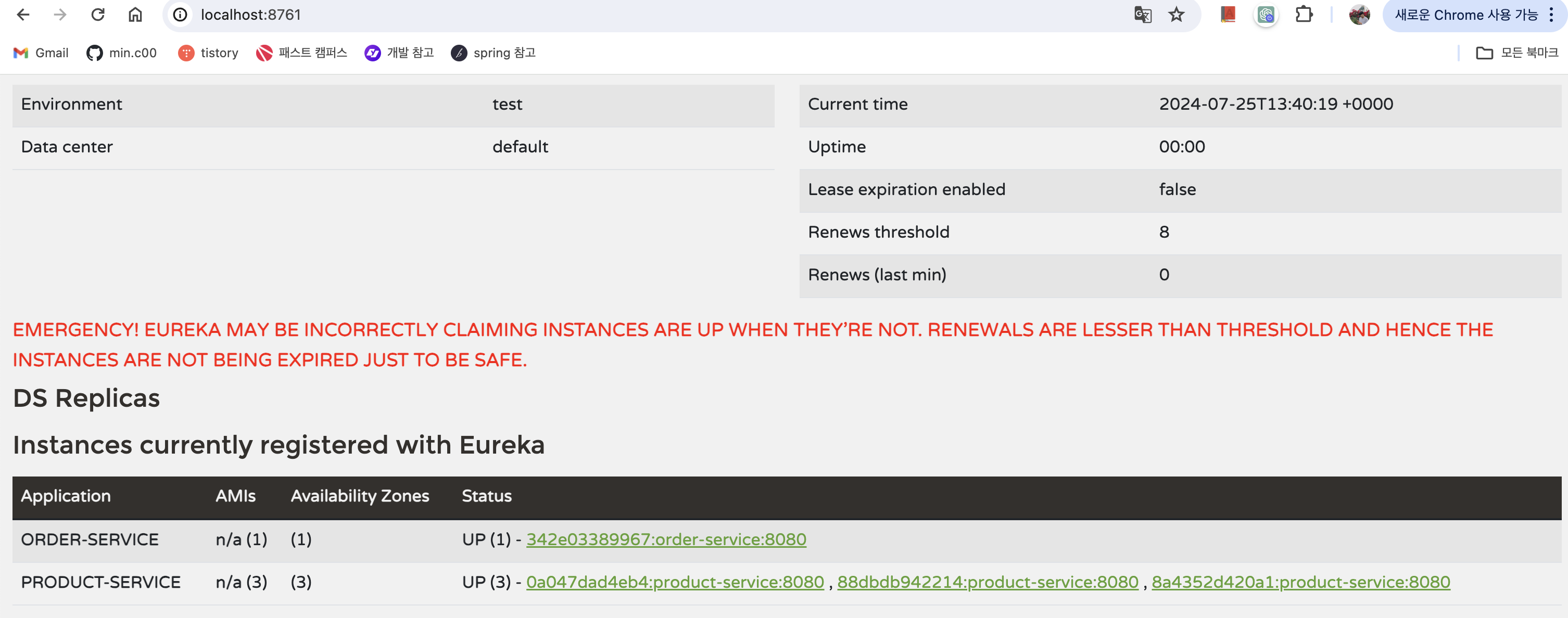
이제 각 엔드포인트를 호출해봅시다. 서버의 ip 호출마다 변경되는 것을 확인할 수 있습니다. 이는 front-api-client가 유레카 서버로부터 가용한 인스턴스를 검색해서 직접 로드밸런싱을 하고 있음을 알 수 있습니다.


더 나아가기
현재 검색 서비스 중 클라이언트 사이드 검색 서비를 구현하기 위해서 Netflix 오픈소스 기술들인 Netflix Hystrix, Netflix Ribbon, Feign Client를 사용했습니다. 다만, 스프링 클라우드는 2019년 1월에 스프링 클라우드 그리니치 v2.1을 출시하면서 Netflix Hystrix, Netflix Ribbon 기술을 유지보수 모드로 전환했습니다. 그래서 Spring Cloud는 다음과 같은 대체 방안을 제시했습니다.
| 현재 컴포넌트 | 대체 컴포넌트 |
| Netflix Hystrix | Resilience4j |
| Netflix Ribbon | Spring Cloud Load Balancer |
다음 기회가 있다면 포스팅에서 현재 사용 중인 두 기술을 각각 Resilience4j, Spring Cloud Load Balancer로 변경해 보는 것도 좋을 것 같습니다.
출처:
https://brunch.co.kr/@springboot/451#comments
'도서 > 스프링으로하는 마이크로서비스 구축' 카테고리의 다른 글
| Messaging System - Apache kafka (2) | 2024.07.12 |
|---|---|
| Event Driven System 이란? (0) | 2024.07.07 |
| Spring Reactor - 동기 vs 비동기, 블로킹 I/O vs 논블로킹 I/O (0) | 2024.06.29 |
| 동시성 문제와 해결 (0) | 2024.06.16 |
| Spring REST Docs, API 문서화 (0) | 2024.06.10 |



